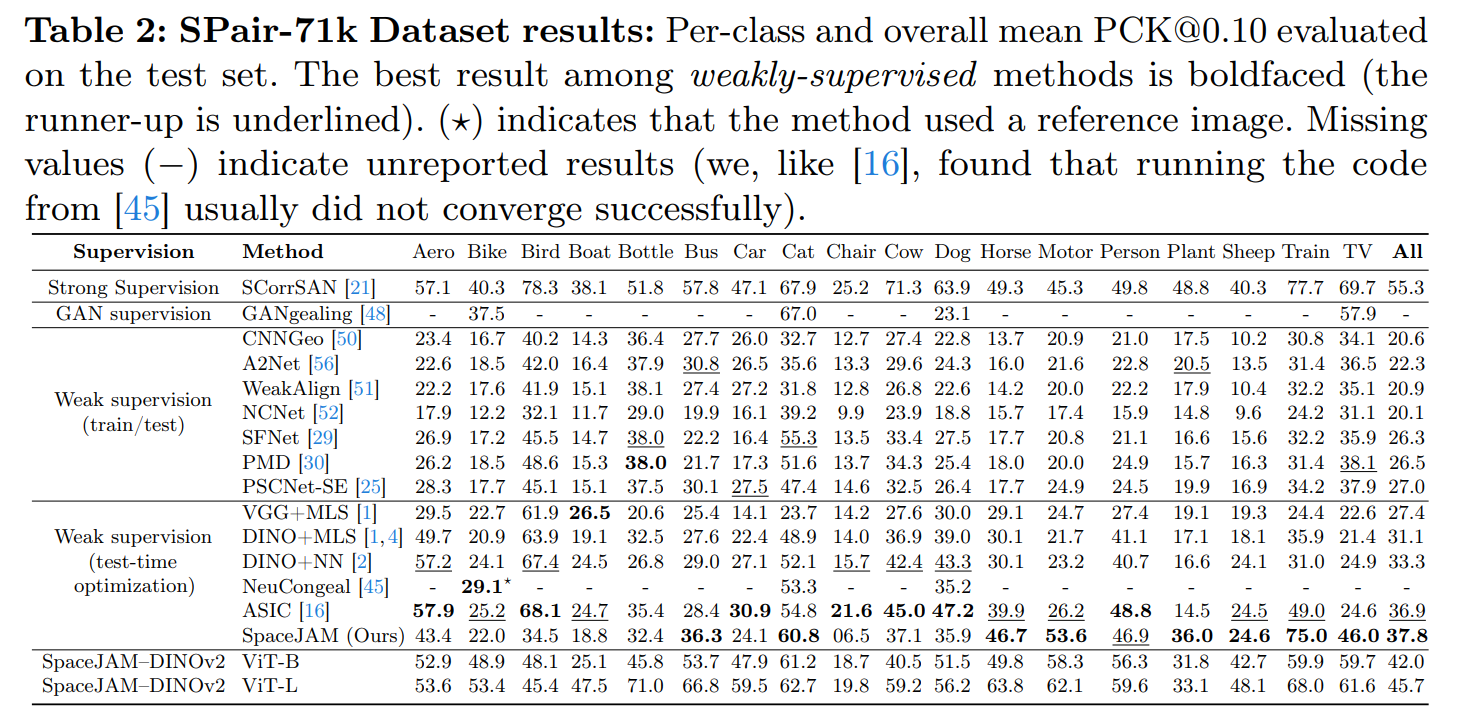
The unsupervised task of Joint Alignment (JA) of images is beset by challenges such as high complexity, geometric distortions, and convergence to poor local or even global optima. Although Vision Transformers (ViT) have recently provided valuable features for JA, they fall short of fully addressing these issues. Consequently, researchers frequently depend on expensive models and numerous regularization terms, resulting in long training times and challenging hyperparameter tuning. We introduce the Spatial Joint Alignment Model (SpaceJAM), a novel approach that addresses the JA task with efficiency and simplicity. SpaceJAM leverages a compact architecture with only ∼16K trainable parameters and uniquely operates without the need for regularization or atlas main- tenance. Evaluations on SPair-71K and CUB datasets demonstrate that SpaceJAM matches the alignment capabilities of existing methods while significantly reducing computational demands and achieving at least a 10x speedup. SpaceJAM sets a new standard for rapid and effective image alignment, making the process more accessible and efficient